I built a better tokens/sec test bench to benchmark inference performance systematically. The key improvement over my previous ad-hoc scripts is that this test bench now measures prefill vs decode separately, along with TTFT, power draw, and efficiency metrics.
The Experiment
I ran the MiniMax M2.5 UD_IQ2_M model (Q2 quantization) across 6x RTX 3090s (144GB total VRAM) with llama.cpp server. The test swept power limits from 100W to 350W per GPU (as DC power draw reported by nvidia-smi):
- 100W, 150W, 200W, 250W, 300W, 350W (unconstrained)
- Context lengths from 4K to 198K tokens
Results
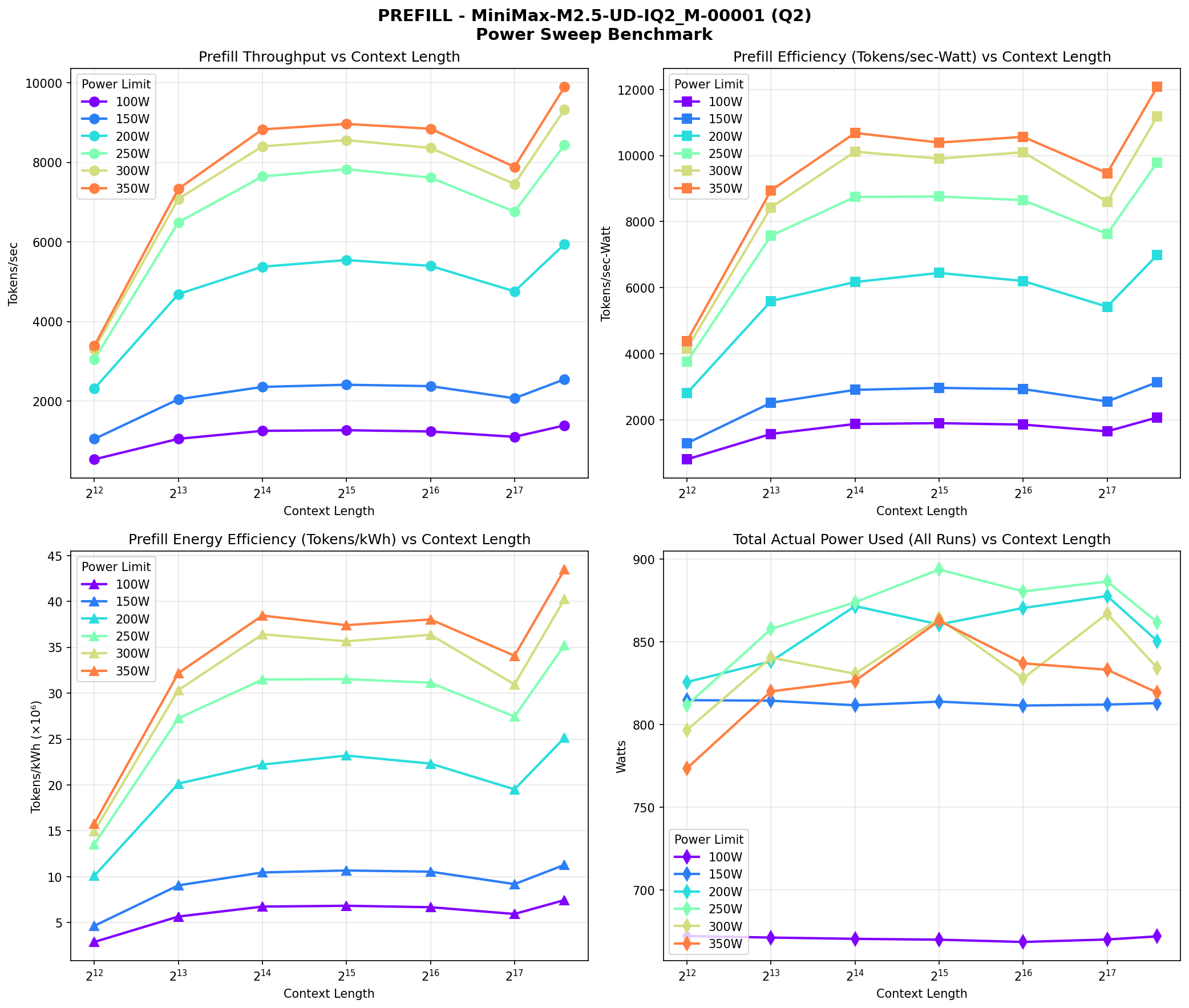
Prefill Performance
| Power Limit | Context | Prefill tps | Efficiency (tok/kWh) |
|---|---|---|---|
| 350W | 198K | 9,893 | 43.5M |
| 300W | 198K | 9,326 | 40.2M |
| 250W | 198K | 8,436 | 35.2M |
| 200W | 198K | 5,941 | 25.1M |
| 150W | 198K | 2,549 | 11.3M |
| 100W | 198K | 1,390 | 7.5M |
Higher power limits deliver higher prefill throughput. At 350W vs 100W, you're getting ~7x more tokens/second during prefill.
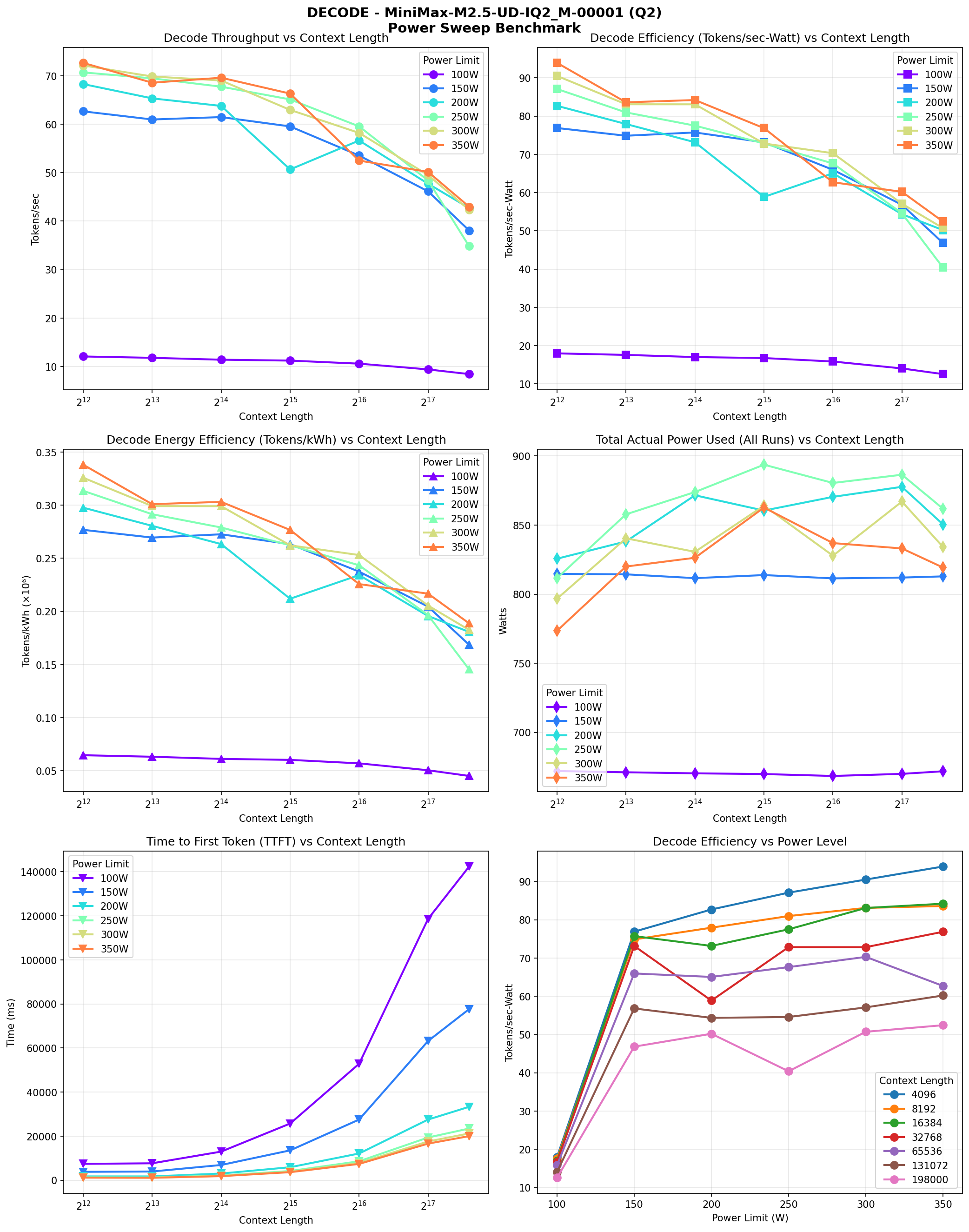
Decode Performance
| Power Limit | Context | Decode tps | Efficiency (tok/kWh) |
|---|---|---|---|
| 350W | 4K | 72.6 | 338K |
| 300W | 4K | 72.1 | 326K |
| 250W | 4K | 70.7 | 314K |
| 200W | 4K | 68.3 | 298K |
| 150W | 4K | 62.6 | 277K |
| 100W | 4K | 12.1 | 65K |
Decode performance gains plateau around 250W-350W (only ~8% improvement going from 250W to 350W). But at 100W, decode is throttled dramatically (only 12 tps vs 72 tps).
Time to First Token (TTFT)
| Power Limit | 4K context | 198K context |
|---|---|---|
| 350W | 1,178 ms | 20,003 ms |
| 300W | 1,207 ms | 21,219 ms |
| 250W | 1,310 ms | 23,458 ms |
| 200W | 1,725 ms | 33,310 ms |
| 150W | 3,803 ms | 77,636 ms |
| 100W | 7,421 ms | 142,324 ms |
TTFT scales roughly linearly with power limit. Going from 100W to 350W gives you ~6-7x faster time to first token.
Key Findings
The Obvious
- TTFT was fastest at 350W - more power = faster prefill
- Tokens/sec was highest at 350W - higher power = higher throughput
- 100W severely limits inference - at 100W, decode drops to ~12 tps, which is painful
The Interesting
- Power draw barely changes with power limit - total system power topped out around 820-900W regardless of whether we set 100W or 350W per GPU. This may be because MiniMax is an MoE model with only ~10B active parameters, so it doesn't demand enough compute to max out the GPUs.
- 350W actually used less power than constrained settings - counterintuitively, the unconstrained 350W limit drew less power than 150W, 200W, and 250W settings. This is likely something to do with how the GPU firmware handles power-constrained vs unconstrained states.
The Bottom Line on Power Limits
Based on this data, power limiting doesn't save energy for inference workloads like MiniMax. The GPUs simply don't use the full power allocation. The real reasons to use power limits are:
- Circuit breaker management - keeping total system power below what your outlets/PSUs can handle
- Peak power management - power limits provide assurance that GPUs won't hit extreme temperatures in warm rooms or poor airflow setups
- GPU longevity - cooler operation may extend component lifespan over time
Charts
The test bench generates detailed charts showing prefill and decode performance across all context lengths and power levels.
Takeaways
- Power limits don't necessarily save energy - MiniMax draws ~670-820W regardless of power limit setting. There's no meaningful efficiency gain.
- 350W delivers the best performance - highest throughput, fastest TTFT, and paradoxically the lowest power consumption.
- 100W should be avoided entirely - you get neither speed nor efficiency. Decode drops to ~12 tps vs 72 tps at higher power, and you generate fewer total tokens per kWh due to the throttling.
- Use power limits for practical reasons - circuit capacity, heat management, or extending GPU life-not energy savings.
- Need to test dense models - these results might be different with dense (non-MoE) models that actually max out GPU power draw.