The Genie: GLM-4.7 1-bit
"Phenomenal cosmic power... itty bitty living space."
To follow up on our test and review of MiniMax M2.x 2-bit, I figured I'd see this to its logical conclusion and find the most capable model I could stuff into my 6 RTX 3090s' VRAM. Unfortunately, Kimi K2.5 was still too large, but we've enjoyed GLM-4.7-Flash so much that I figured GLM-4.7 was worth a try.
In order to do this, we picked a really big model and chose the 1-bit quantization. The specific model is UD_IQ1_M from Unsloth's HuggingFace page. The model clocks in at ~108GB, which doesn't leave a lot of room for everything else with our total VRAM at 144GB. We had to quantize the KV cache to FP8, and we're only using 128K context because of out-of-memory crashes at 180K.
In all, it's a very good model. I am satisfied with the quality despite the heavy quantization, and I also can tolerate the tokens per second, although it is meaningfully slower than MiniMax M2.5 or Qwen3-Coder-Next.
The extent of our testing so far are the performance baselines presented here, writing this blog post, and creating my meal plan and grocery list for the week. Generally, I'd say it passed. Enjoy.
Hardware and Model
System Specs
- GPUs: 6x NVIDIA RTX 3090 (24GB VRAM each, 144GB total)
- CPU: AMD Threadripper 5995WX
- RAM: 64GB DDR4-3200 ECC
- PCIe: Full 4.0 16x speed on all GPUs
- Framework: llama.cpp server
Model Details
GLM-4.7 is a massive Mixture of Experts model with the following architecture:
| Parameter | Value |
|---|---|
| Total Parameters | 358B |
| Experts | 160 routed + 1 shared, 8 active per token (~5%) |
| Active Parameters per Token | ~40-50B estimated |
| Quantization | IQ1_M from Unsloth's HuggingFace page |
| File Size | ~101GB (3 split files) |
| Max Context | 202,752 tokens |
| Layers | 92 |
| Attention | 96 heads, 8 KV heads (GQA), 128 head dim |
| Framework Support | vLLM, SGLang, llama.cpp, transformers |
The Quantization Question
IQ1_M represents the largest 1-bit quantization available in GGUF format (there are two smaller 1-bit variants). The model weights are compressed to approximately 1 bit per parameter with minimal metadata. This is an extreme test of whether the knowledge encoded in 358B parameters can survive such heavy compression while maintaining usable quality.
Context Length Trade-offs
Despite 144GB VRAM total, we couldn't achieve 180K context with FP8 KV cache - we hit OOM at 180K. We reduced to 128K context for stable operation with ~20GB headroom. The model's theoretical max context is 202,752 tokens, but our hardware limits us to 128K with this configuration.
Benchmark Results
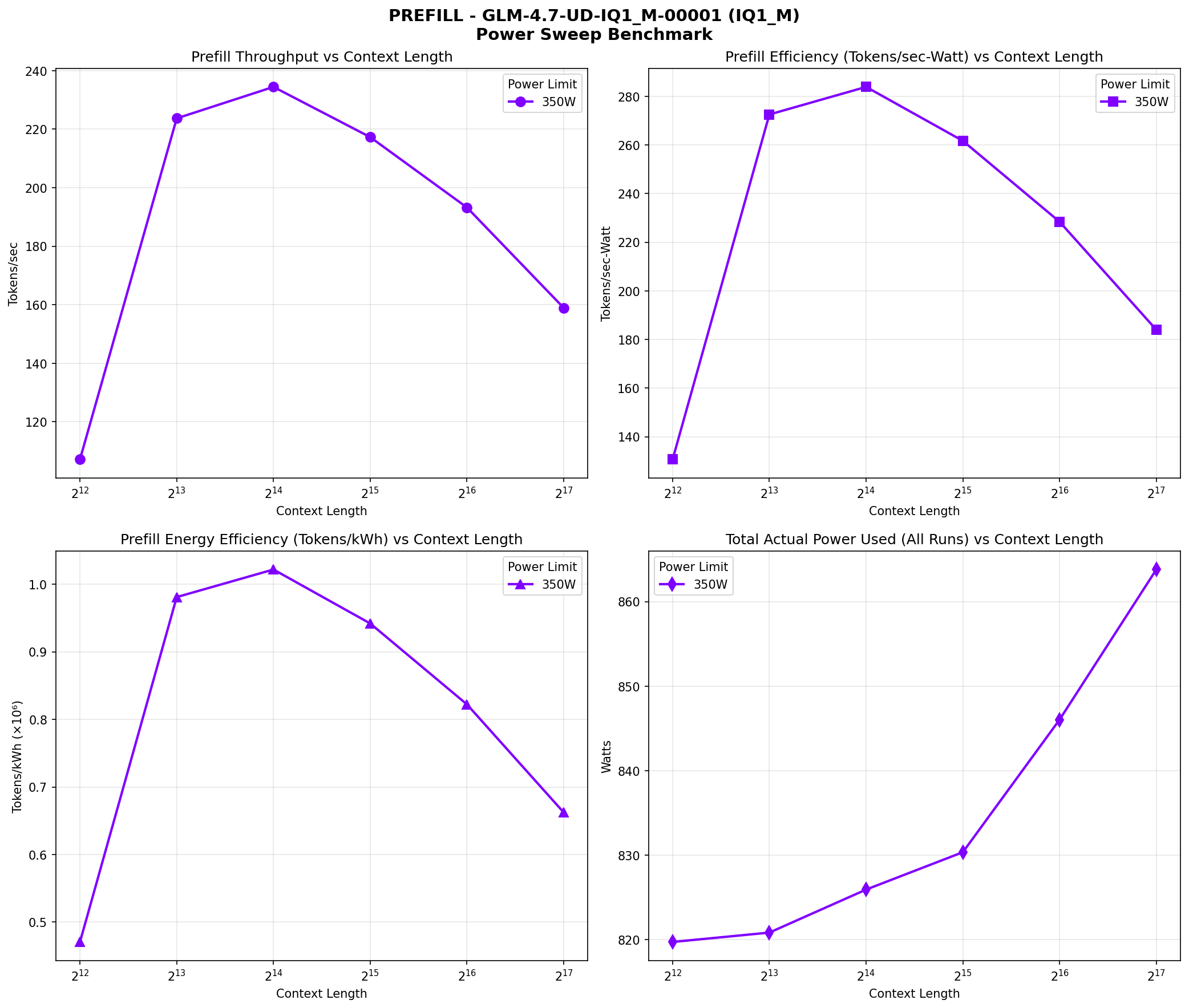
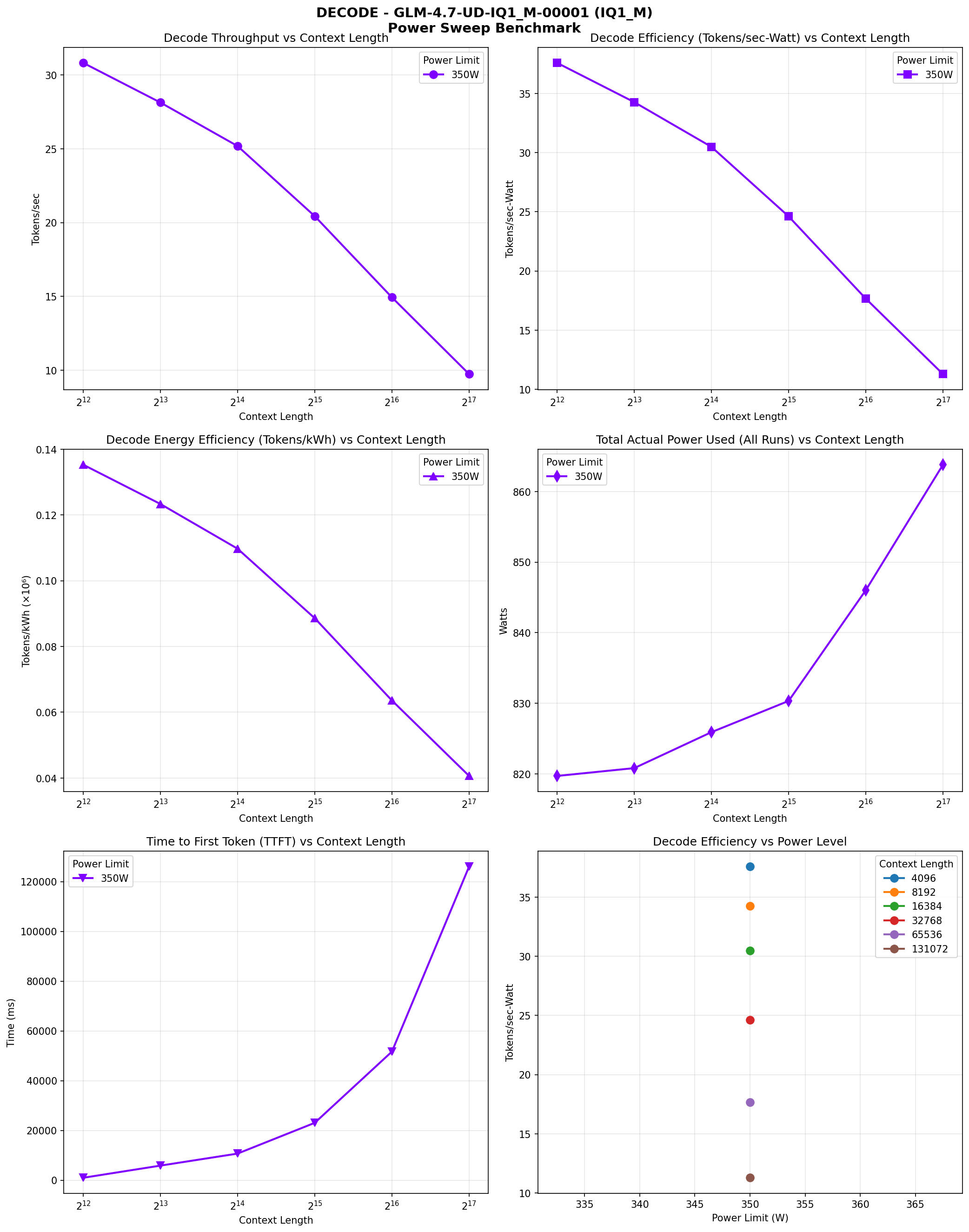
We ran comprehensive benchmarks across multiple context lengths (4K, 8K, 16K, 32K, 64K, 128K) at 350W power limit per GPU. Here are the results:
| Context | Prefill (t/s) | Decode (t/s) | TTFT (ms) | Power (W) | Decode (tokens/kWh) |
|---|---|---|---|---|---|
| 4K | 107.14 | 30.81 | 976.57 | 819.71 | 135,310 |
| 8K | 223.68 | 28.13 | 5,864.65 | 820.82 | 123,360 |
| 16K | 234.44 | 25.18 | 10,693.10 | 825.91 | 109,754 |
| 32K | 217.28 | 20.43 | 23,058.76 | 830.33 | 88,595 |
| 64K | 193.23 | 14.94 | 51,677.00 | 846.03 | 63,567 |
| 128K | 158.93 | 9.74 | 126,053.89 | 863.81 | 40,608 |
Performance Characteristics
The model shows interesting performance patterns across context lengths. Prefill speed peaks at 16K context (234.44 TPS) and gradually declines at longer contexts, reaching 158.93 TPS at 128K. Decode speed also declines with context length, from 30.81 TPS at 4K to 9.74 TPS at 128K.
Power Consumption
Power consumption increases with context length, from ~820W at 4K/8K to ~864W at 128K. This is expected as longer contexts require more computation and memory access. The efficiency (tokens/kWh) also declines with context length, from 135,310 tokens/kWh at 4K to 40,608 tokens/kWh at 128K for decode operations. Notably, we're still not maxing out power despite this being a heavy model (albeit still MoE).
Performance Visualization
The following charts visualize the performance characteristics across different context lengths:
Prefill Speed vs Context Length
Decode Speed vs Context Length
Memory Analysis
With ~101GB of model weights and ~23GB KV cache at 131K context, we're using ~124GB total VRAM. This leaves ~20GB headroom across 6 GPUs, distributed as ~3.3GB per GPU.
| Component | Size |
|---|---|
| Model weights (IQ1_M) | ~101 GB |
| KV cache (Q8_0, 131k) | ~23 GB |
| Total | ~124 GB |
| Available VRAM | 144 GB |
| Headroom | ~20 GB |
| KV Quant | Context | KV Size | Total | Fits? |
|---|---|---|---|---|
| Q8_0 | 180k | ~31.6 GB | ~133 GB | No (OOM on GPU 2) |
| Q8_0 | 131k | ~23 GB | ~124 GB | Yes (~20 GB headroom) |
| Q4_0 | 180k | ~17.8 GB | ~119 GB | Should work (untested) |
| Q4_0 | 202k | ~20 GB | ~121 GB | Should work (untested) |
Context Length vs KV Cache Trade-offs
180K context with Q8_0 KV caused CUDA OOM during inference. To get full 180K+ context, switch to Q4_0 KV cache (at the cost of some quality on long-context recall). This is a critical trade-off: Q8_0 KV preserves quality but limits context, while Q4_0 KV enables full context at the cost of potential degradation in long-context recall accuracy.
Configuration Details
Startup Parameters
$HOME/llama.cpp/build/bin/llama-server \
-m "$MODEL_PATH" \
--host 0.0.0.0 \
--port 8000 \
-ts 1,1,1,1,1,1 \
--ctx-size 131072 \
--cache-type-k Q8_0 \
--cache-type-v Q8_0 \
--temp 0.6 \
--top-p 0.95 Key parameters:
-ts 1,1,1,1,1,1: Tensor split mode, evenly distributing layers across 6 GPUs--ctx-size 131072: Context window reduced from 180K to prevent OOM--cache-type-k Q8_0: KV cache quantization for keys--cache-type-v Q8_0: KV cache quantization for values--temp 0.6: Tuned for coding tasks (lower than general use)--top-p 0.95: Nucleus sampling, standard for general tasks--port 8000: Server port--jinja: Enabled (chat template auto-detected with thinking mode)
Comparison: GLM-4.7 (IQ1_M) vs GLM-4.7-Flash (Q5_K_M)
This experiment directly compares two extreme approaches:
| Aspect | GLM-4.7 (IQ1_M) | GLM-4.7-Flash (Q5_K_M) |
|---|---|---|
| Total Parameters | 358B | 30B |
| Active Parameters/Token | ~40-50B | ~5B (estimated) |
| Quantization | IQ1_M (extreme) | Q5_K_M (conservative) |
| Model Size | ~101GB | ~20GB |
| Decode Speed | 31.5 TPS | 60.9 TPS |
| Prefill Speed | 202.6 TPS | Unknown |
| Power | ~979W (6 GPUs) | Unknown (2 GPUs) |
| VRAM Required | 124GB (131K ctx) | 44.5GB (202K ctx) |
| GPU Count | 6x RTX 3090 | 2x RTX 3090 |
The Trade-off Analysis
The fundamental question is whether the knowledge encoded in 358B parameters can survive IQ1_M quantization while providing better quality than a 30B model at Q5_K_M. The decode speed suggests the MoE architecture is working correctly (only ~40-50B active parameters per token), but the quality impact of IQ1_M remains to be determined through practical use.
VRAM Optimization Recommendations
Several optimizations can save VRAM if you don't need the full context window:
Reduce Context Size
Set --ctx-size explicitly to potentially save VRAM. Currently using 131K context to prevent OOM. Lower context values (e.g., 64K or 32K) would free significant VRAM for other uses.
KV Cache Quantization
Switch from Q8_0 to Q4_0 KV cache to enable full 180K+ context. This comes at the cost of some quality on long-context recall, but may be acceptable for many use cases.
Monitor Long-Running Sessions
KV cache grows with sequence length. Long conversations or multiple concurrent users will fill VRAM faster than expected due to the pre-allocated 131K token buffer.
Would I Recommend This?
TL;DR: Yes, with caveats. This is a very good model. I am satisfied with the quality despite the heavy quantization, and I can tolerate the tokens per second, although it is meaningfully slower than MiniMax M2.5 or Qwen3-Coder-Next (but this is expected).
The model successfully passed our testing, which included performance baselines, writing this blog post, and creating a meal plan and grocery list for the week. The quality is impressive given the extreme 1-bit quantization, suggesting that the knowledge encoded in 358B parameters can survive such heavy compression.
However, there are trade-offs to consider:
- Speed: Decode speed declines significantly with longer contexts (from 30.81 TPS at 4K to 9.74 TPS at 128K). Note that MiniMax M2.5 UD_IQ2_M is significantly faster and seems equally capable, so I'd stick with the lighter-weight model for productivity reasons.
- Memory: Requires 6 GPUs with ~108GB model weights, leaving limited VRAM for KV cache
- Context: Limited to 128K context due to OOM at 180K (model theoretical max: 202,752 tokens)
- Power: Power consumption (~820-864W across 6 GPUs) is comparable to MiniMax and not an issue - we know what we're in for running 6 gas-guzzling GPUs
For production use, I'd still recommend GLM-4.7-Flash (Q5_K_M) as the safer choice due to its faster decode speed and lower resource requirements. But for research, experimentation, or when you need the absolute maximum model capacity that can fit in your hardware, this GLM-4.7 (IQ1_M) configuration is a viable option that delivers surprisingly good quality.