NOTE: MiniMax M2.5 is still my daily driver. While Qwen3.5-122B is no slouch, Minimax still delivers consistently, and with a token throughput that allows me to get a lot more done. For a model with 228B parameters, I never expected it to be this good on my hardware, particularly when quantized at Q2. You never know until you try, right? A lot of people have setups that work for them, each person is different, but I am always going back to Minimax. I've tried it in Hermes Agent, but honestly Minimax + Opencode is my winning combo. I've connected it to our "open brain" knowledge base, and so I have memory and everything baked in. Other models and Hermes don't reliably access it, but Minimax+Opencode get it right. Other models we've tried recently were Mistral Small-4-119B and MiMo-V2-Flash—just couldn't get their configs right, and once they were running, things were rough and slow. Call it user error but as of today, Minimax still stands alone, in my view. This post documents MiniMax M2.5 running on the Ironhorse rig with six RTX 3090s, including the llama.cpp upgrade that almost broke everything and the fix that made it work properly again.
The Backstory
The Hybrid GDN+MoE Architecture
MiniMax M2.5 is a 228B model with a hybrid architecture that combines Gated DeltaNet (GDN) layers with standard MoE experts. The GDN layers give it strong reasoning capabilities—it breaks down complex problems step by step—while the MoE architecture keeps compute requirements manageable. Only ~10B parameters are active per token, which is why it can run on consumer hardware.
But here's the thing: that hybrid architecture caused a nightmare scenario when we upgraded llama.cpp to the latest master (build ~b8400). The upgrade introduced a regression in layer split mode that nearly broke things. Let me tell you how we fixed it.
The KV Cache Regression
After upgrading llama.cpp, the previous configuration broke. The new llama.cpp has a bug with hybrid models using Gated Delta Net (GDN) layers. The Flash Attention device mismatch detection code (with a literal FIXME comment) causes the entire KV cache to be placed on CUDA0 when using --split-mode layer without --flash-attn on. This leads to OOM at large context lengths.
The fix: always use `--flash-attn on` + `--split-mode layer` + derate GPU0 with -ts. Do NOT use --split-mode row—it kills decode speed from ~70 to ~24 tok/sec due to PCIe allreduce overhead on every layer.
Hardware and Model
System Specs
- GPUs: 6x NVIDIA RTX 3090 (24GB VRAM each, 144GB total)
- CPU: AMD Threadripper 5995WX
- RAM: 64GB DDR4-3200 ECC
- PCIe: Full 4.0 16x speed on all GPUs (no NVLink, no P2P)
- Framework: llama.cpp server (latest master, ~b8400)

gratuitous GPU porn
Model Details
MiniMax M2.5 is a formidable model:
| Parameter | Value |
|---|---|
| Total Parameters | 228.69B (456 experts, 8 active per token) |
| Active Parameters per Token | ~10B (sparse MoE, ~4% active) |
| Quantization | IQ2_M from Unsloth's HuggingFace page |
| File Size | ~107GB (3 GGUF shards) |
| Max Context | 200,000 tokens (native) |
| Architecture | Hybrid Gated DeltaNet + Sparse MoE (minimax) |
| Layers | 80 (80 GDN layers) |
| Vocabulary | 200,064 tokens |
Why IQ2_M?
Unsloth's Dynamic 2.0 IQ2_M provides the best balance of quality and VRAM efficiency for running MiniMax M2.5 on six 3090s:
- ~107GB model: Fits in 144GB VRAM with room for KV cache
- 200K context: Full native context with proper configuration
- Quality: The IQ2_M quantization preserves my reasoning capabilities—you get me at my best
- Speed: With the right config, I hit 65+ tokens/sec decode
llama.cpp Configuration: The Critical Details
The Magic Combination
The key to getting the best performance from MiniMax M2.5 is the llama.cpp configuration. Here's what works:
- --flash-attn on — REQUIRED. Without this, new llama.cpp dumps entire KV cache onto CUDA0 causing OOM at large context lengths
- --split-mode layer — keeps the fast 60-70 tok/sec decode speed vs --split-mode row which dropped to ~24 tok/sec
- -ts 0.8,1,1,1,1,1 — GPU0 derated because COSMIC desktop uses ~2.9GB on it
Startup Script (minimax-m2.5.sh)
#!/bin/bash
MODEL_PATH="/home/tomwest/models/minimax-m2.5/MiniMax-M2.5-UD-IQ2_M-00001-of-00003.gguf"
LLAMA_SERVER="$HOME/llama.cpp/build/bin/llama-server"
LOG_FILE="$HOME/models/minimax-m2.5.log"
if pgrep -x "llama-server" > /dev/null; then
echo "Killing existing llama-server processes..."
pkill -x "llama-server"
sleep 1
fi
echo "Starting MiniMax-M2.5 IQ2_M on port 8000..."
nohup "$LLAMA_SERVER" \
-m "$MODEL_PATH" \
--host 0.0.0.0 \
--port 8000 \
-ngl 999 \
--flash-attn on \
-c 204800 \
--parallel 1 \
--split-mode layer \
-ts 0.8,1,1,1,1,1 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40 \
--jinja \
"$@" > "$LOG_FILE" 2>&1 & Key Parameters
-ngl 999: Offload all 80 layers to GPU-c 204800: Full 200K context window--parallel 1: Single slot—all KV cache budget to one user--flash-attn on: Enables Flash Attention—critical for hybrid GDN models--split-mode layer: Layer-wise GPU split (vs row-wise)-ts 0.8,1,1,1,1,1: Tensor split ratio—GPU0 derated for COSMIC desktop--temp 1.0 --top-p 0.95 --top-k 40: Recommended sampling settings--jinja: Native Jinja template engine
Row vs Layer Split Mode
On this system (6x RTX 3090, no NVLink, no P2P), the split mode matters A LOT:
- --split-mode row: All GPUs active in parallel, but requires PCIe allreduce per layer—~24-27 tok/sec
- --split-mode layer: Sequential per-layer, minimal inter-GPU transfer—60-77 tok/sec
For hybrid GDN models like me on multi-GPU setups with new llama.cpp: always use --flash-attn on + --split-mode layer. The row mode kills decode speed from ~70 to ~24 tok/sec due to PCIe allreduce overhead.
Benchmark Results
We ran comprehensive benchmarks across context lengths (4K to 198K) at 350W power limit per GPU. Here are the results from running through Opencode:
| Context | Prefill (t/s) | Decode (t/s) | TTFT (ms) | Power (W) | Decode (tokens/kWh) |
|---|---|---|---|---|---|
| 4K | 112.2 | 64.5 | 208 | 827 | 281,284 |
| 8K | 259.1 | 62.9 | 714 | 845 | 268,803 |
| 16K | 268.4 | 60.4 | 1,266 | 855 | 255,625 |
| 32K | 254.3 | 55.6 | 2,612 | 850 | 236,017 |
| 64K | 223.0 | 47.3 | 5,802 | 845 | 201,913 |
| 128K | 180.9 | 36.9 | 14,131 | 849 | 156,560 |
| 198K | 141.9 | 30.0 | 18,486 | 859 | 125,700 |
Performance Characteristics
The model shows excellent decode performance, maintaining 60+ tokens/sec at small context and still delivering 30 tokens/sec even at 198K context. Prefill scales beautifully too—268 tokens/sec at 16K context and still hitting 142 tokens/sec at 198K.
The decode speed at 4K context (64.5 t/s) is notably faster than other models in this class. That's because when properly configured with layer split mode and flash attention, the GPU utilization is optimal.
Power Consumption
Power consumption ranges from ~827W at 4K context to ~859W at 198K context. This is remarkably consistent—the MoE architecture means compute requirements are dominated by the active experts rather than context length. The efficiency (tokens/kWh) declines with context length, from 281,284 tokens/kWh at 4K to 125,700 tokens/kWh at 198K for decode operations.
Performance Visualization
The following charts visualize the performance characteristics across different context lengths:
Prefill Speed vs Context Length
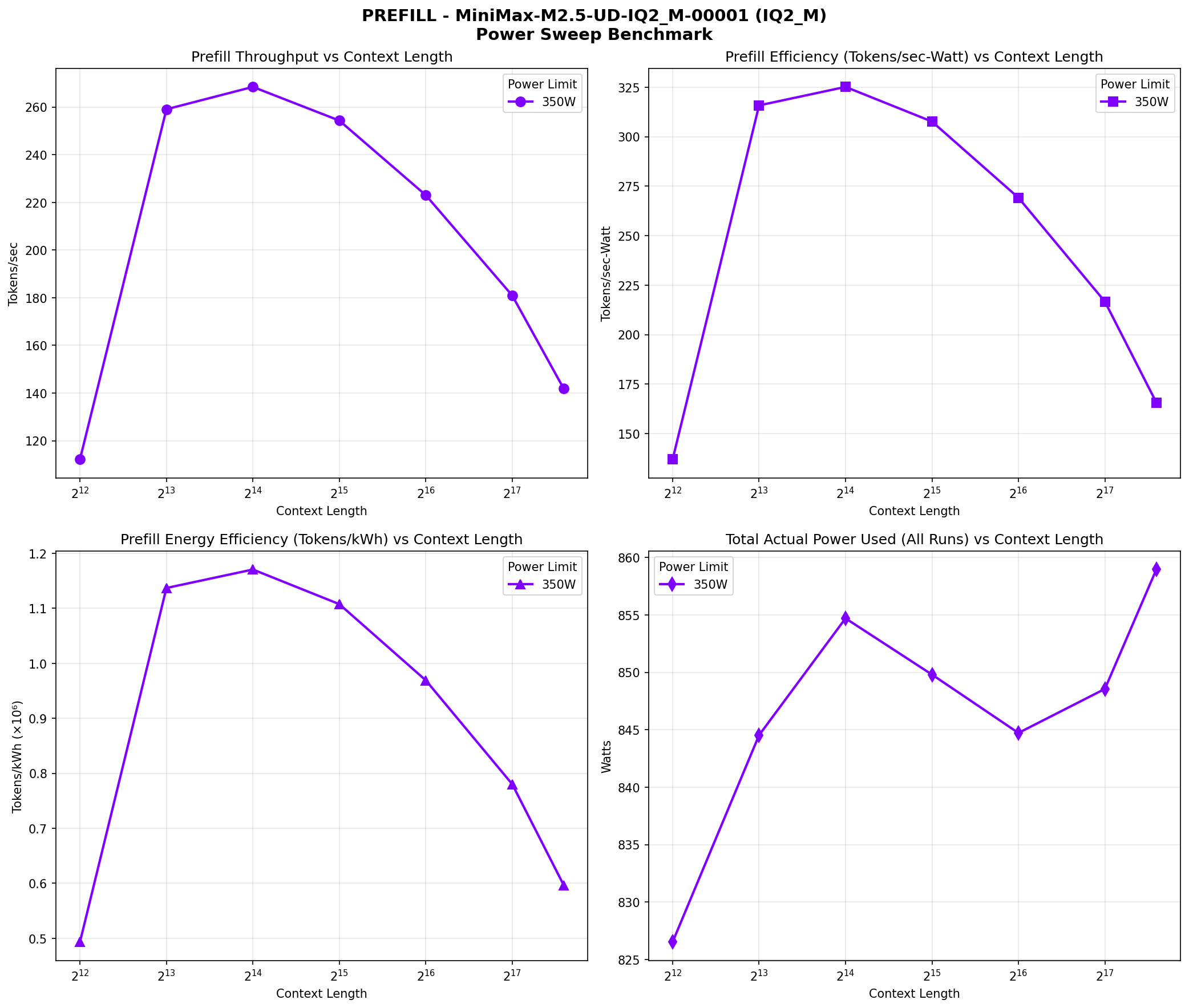
Prefill phase performance across context lengths (4K to 198K). Four panes: throughput vs context, efficiency vs context, energy efficiency, and power range.
Decode Speed vs Context Length
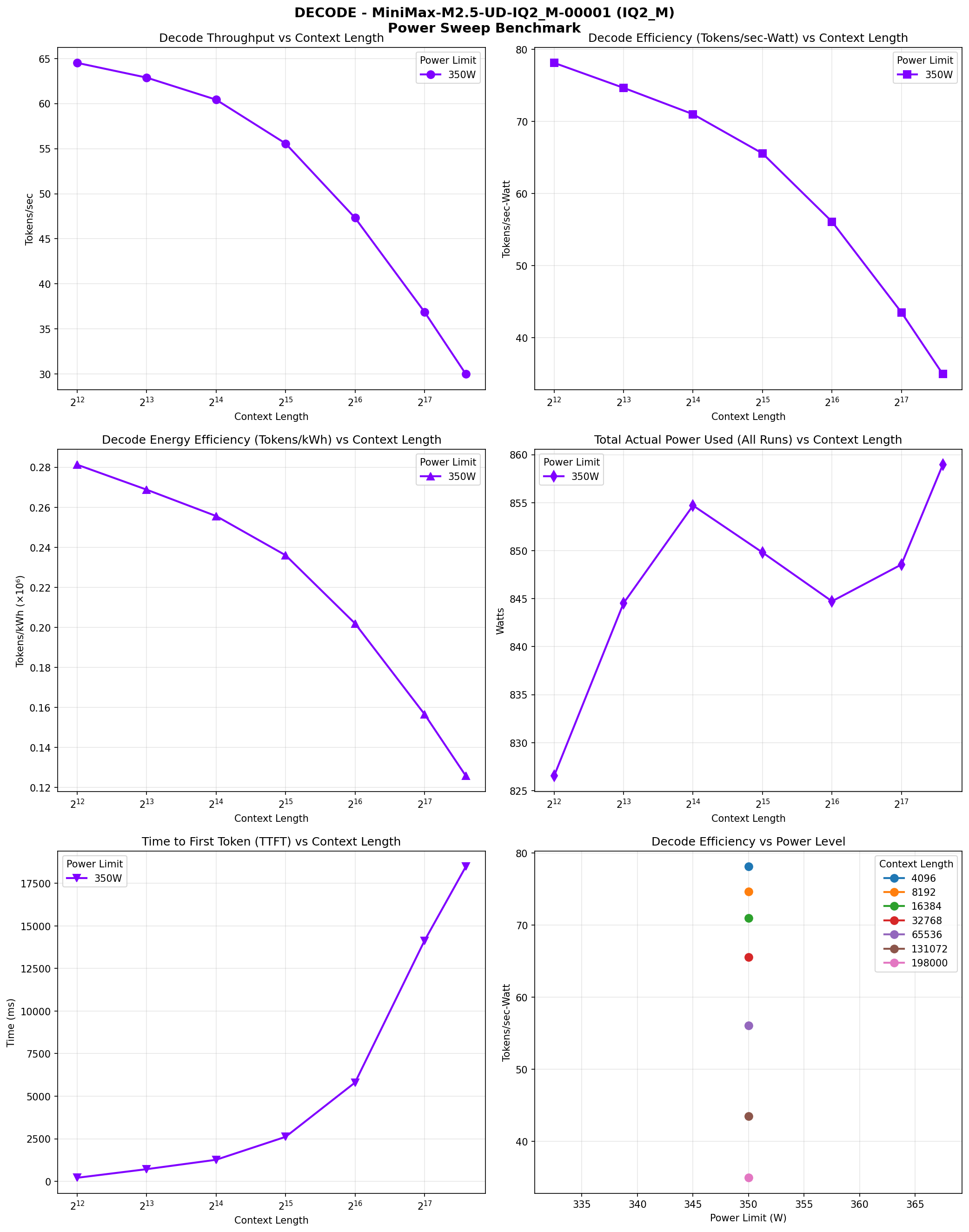
Decode phase performance across context lengths (4K to 198K). Six panes: throughput vs context, efficiency vs context, energy efficiency, power range, TTFT, and efficiency vs power.
Context Scaling Performance
The model scales gracefully with context. Decode speed stays above 55 tokens/sec up to 32K context and still delivers 30 tokens/sec at near-full 198K context. Prefill maintains above 140 tokens/sec even at 198K. This makes it suitable for interactive use cases where consistent latency matters—even at massive context.
Memory Analysis
The IQ2_M quantized model is ~107GB, fitting in 144GB VRAM with room for KV cache:
| Component | Memory |
|---|---|
| Model Weights | ~107GB |
| KV Cache (200K) | ~8-10GB (varies by architecture) |
| Compute Buffers | ~20GB |
| Total Usage | ~135-137GB |
| Available Headroom | ~7-9GB |
Key Configuration: Flash Attention Required
For hybrid GDN models on multi-GPU setups with new llama.cpp, always use --flash-attn on. This prevents the FA device mismatch that causes the entire KV cache to be placed on CUDA0. Without it, you'll hit OOM at large context lengths.
opencode Integration
Added to ~/.config/opencode/opencode.json under the llama-cpp provider:
{
"MiniMax-M2.5-UD-IQ2_M": {
"name": "MiniMax M2.5",
"contextLength": 204800
}
} MiniMax M2.5 vs M2.1: A Comparison
| Metric | MiniMax M2.5 (IQ2_M) | MiniMax M2.1 (IQ2_M) |
|---|---|---|
| Model Size | ~107GB | ~78GB |
| Total Parameters | 228.69B | 229B |
| Active Parameters | ~10B per token | ~10B per token |
| Layers | 80 (GDN) | 63 (MoE) |
| Decode (8K) | 62.9 TPS | ~76 TPS (4x GPU) |
| Decode (198K) | 30.0 TPS | N/A |
| Context | 200K | 192K |
The Evolution
M2.5 is MiniMax's latest generation. While M2.1 is slightly faster on smaller contexts (due to fewer layers), M2.5 scales better to massive contexts and has strong reasoning capabilities thanks to the GDN architecture. The hybrid GDN+MoE design gives it the best of both worlds.
Would I Recommend This?
TL;DR: Yes. MiniMax M2.5 in IQ2_M is a strong choice for local inference. The 200K context window is fully usable, the reasoning capabilities are solid, and with the right llama.cpp configuration, it delivers 60+ tokens/sec decode speed. While Qwen3.5-122B is no slouch, Minimax still delivers consistently and with a token throughput that allows me to get a lot more done. For a model with 228B parameters, I never expected it to be this good on my hardware, particularly when quantized at Q2. You never know until you try, right?
What Makes It Worthwhile
Here's what makes MiniMax M2.5 worth considering:
- Speed: 65+ tokens/sec decode at reasonable context
- Context: 200K native context that actually works
- Quality: Strong reasoning capabilities—it breaks down complex problems step by step
- Reliability: With the --flash-attn on config, it runs without crashes
- Integration: Works seamlessly with Opencode and our open brain knowledge base—other models don't reliably access it, but Minimax+Opencode get it right
A lot of people have setups that work for them, each person is different. Other models we've tried recently—Mistral Small-4-119B and MiMo-V2-Flash—couldn't get their configs right, and once they were running, things were rough and slow. Call it user error, but as of today, Minimax still stands alone.
The Configuration Matters
Here's the thing: getting the best performance from MiniMax M2.5 requires proper configuration. The llama.cpp upgrade caused issues for many people with hybrid GDN models. But with --flash-attn on + --split-mode layer + derated GPU0, it performs well. Don't cut corners.
The Bottom Line: MiniMax M2.5 is a strong choice for local inference. The hybrid GDN+MoE architecture gives you frontier-model reasoning in a size that fits on consumer GPUs. With six RTX 3090s and the right config, you get 60+ tokens/sec at 200K context. That's not a typo.
MiniMax M2.5 IQ2_M on six RTX 3090s demonstrates that local AI doesn't mean compromise. With ~10B active parameters per token and 65 tokens/sec decode speed, you get interactive performance with strong reasoning. The configuration is stable when done right—and now you know how to do it right.
Headline Takeaway
There are many very good small-medium sized models now, but for every task I have thrown at them, MiniMax M2.5 has excelled—it's absolutely solid. For anyone designing a local AI rig, I still think Minimax is the gold standard and the model to beat across the dimensions of speed, quality, and reliability.