NOTE: This post documents our journey with Qwen3.5-397B-A17B in UD-TQ1_0 (1-bit) quantization. After successfully running MiniMax M2.5 and GLM-4.7, we pushed further into extreme quantization territory with this 397B-parameter MoE model.
The Backstory
The 1-Bit Experiment
After proving that 2-bit quantization (IQ2_M) worked beautifully for MiniMax M2.1 on quad 3090s, and that GLM-4.7 at 1-bit (IQ1_M) was viable on sextet 3090s, the next logical step was clear: push the largest possible model into our 144GB VRAM. Qwen3.5-397B-A17B in UD-TQ1_0 format is the largest model we've attempted yet, compressing 397B parameters into ~88GB.
The Compatibility Challenge
Initial attempts with llama.cpp build b7991 hit a critical Jinja template crash on tool calls. The model's chat template wasn't recognized, causing llama.cpp to fall back to Hermes 2 Pro format. When the model generated tool calls, the template tried to call `tool_call.arguments|items` on a JSON string instead of a dict, producing 500 errors in a loop. Rebuilding at b8137 with the proper Qwen3.5 support commits fixed everything.
Hardware and Model
System Specs
- GPUs: 6x NVIDIA RTX 3090 (24GB VRAM each, 144GB total)
- CPU: AMD Threadripper 5995WX
- RAM: 64GB DDR4-3200 ECC
- PCIe: Full 4.0 16x speed on all GPUs
- Framework: llama.cpp server (build b8137+)
Model Details
Qwen3.5-397B-A17B is the largest Mixture of Experts model we've run locally:
| Parameter | Value |
|---|---|
| Total Parameters | 397B |
| Active Parameters per Token | ~17B (sparse MoE, ~4.3% active) |
| Experts | 512 routed + 1 shared (10 routed per token) |
| Quantization | UD-TQ1_0 from Unsloth's HuggingFace page |
| File Size | ~88GB (single GGUF file) |
| Max Context | 262,144 tokens (native) |
| Architecture | Hybrid Gated DeltaNet + Sparse MoE |
| Layers | 61 |
| Framework Support | llama.cpp, vLLM, SGLang, transformers |
Why UD-TQ1_0?
Unsloth's UD-TQ1_0 (Uniform Dynamic 1-bit) quantization compresses the model to ~88GB while preserving quality. This is the most aggressive quantization that still produces usable results:
- IQ1_M variants: Multiple 1-bit options exist, but UD-TQ1_0 provides the best quality/size balance
- 88GB model: Leaves ~56GB headroom for KV cache and context
- 262K context: Full native context with q8_0 KV cache quantization
The UD-TQ1_0 method uses dynamic per-layer quantization, allocating more bits to critical layers while maintaining 1-bit average. This is more sophisticated than uniform 1-bit approaches.
llama.cpp Compatibility
The Jinja Template Crash
Build b7991 (57487a64c) initially loaded and ran the model but hit a critical bug on tool calls:
Error: Unknown (built-in) filter 'items' for type String
The model's embedded chat template wasn't recognized, causing llama.cpp to fall back to Hermes 2 Pro format. When the model generated tool calls, the Hermes template tried to call `tool_call.arguments|items` on a JSON string (not a dict), producing 500 errors in a loop.
The Fix: Rebuild at b8137
Key commits between b7991 and b8137 that resolved our issues:
| Commit | Description |
|---|---|
da38c9df | models: fix qwen3.5 beta/gate shapes (#19730) |
39e4b1dc9 | common: fix gpt-oss Jinja error when assistant message has both content and thinking with tool calls (#19704) |
5452d736f | jinja: correct stats for tojson and string filters (#19785) |
94b0200a0 | common: merge qwen3-coder and nemotron nano 3 parsers (#19765) |
After rebuilding, the chat template is detected natively (proper format) with thinking mode enabled. No more Hermes 2 Pro fallback, no more 500 errors.
Build Configuration
cmake /home/tomwest/llama.cpp -B /home/tomwest/llama.cpp/build \ -DBUILD_SHARED_LIBS=OFF \ -DGGML_CUDA=ON \ -DGGML_CUDA_FA_ALL_QUANTS=ON cmake --build /home/tomwest/llama.cpp/build --config Release -j$(nproc) --clean-first
GGML_CUDA_FA_ALL_QUANTS=ON compiles Flash Attention kernels for all KV cache quantization types (q8_0, q4_0, etc.), not just f16/f32. This is required for efficient inference when using quantized KV cache.
Configuration Details
Startup Script
#!/bin/bash
MODEL_PATH="/home/tomwest/models/qwen-3.5/Qwen3.5-397B-A17B-UD-TQ1_0.gguf"
LLAMA_SERVER="$HOME/llama.cpp/build/bin/llama-server"
LOG_FILE="$HOME/models/qwen-3.5.log"
nohup "$LLAMA_SERVER" \
-m "$MODEL_PATH" \
--host 0.0.0.0 \
--port 8000 \
-ngl 999 \
-c 262144 \
--parallel 1 \
-ctk q8_0 \
-ctv q8_0 \
--split-mode layer \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--jinja \
"$@" Key Parameters
-ngl 999: Offload all 61 layers to GPU-c 262144: Full native 262K context window--parallel 1: Single slot—all KV cache budget to one user-ctk q8_0 -ctv q8_0: Quantize KV cache keys and values (halves KV memory)--split-mode layer: Layer-wise GPU split (equal distribution)--temp 0.6 --top-p 0.95 --top-k 20: Recommended for thinking mode--jinja: Native Jinja template engine (required for Qwen3.5)
KV Cache Quantization
The 88GB model across 144GB VRAM leaves ~56GB for KV cache. At full f16 precision, 262K context would need more than that. Using -ctk q8_0 -ctv q8_0 halves the KV memory footprint while remaining near-lossless, making 262K context fit comfortably.
The GGML_CUDA_FA_ALL_QUANTS=ON build flag is essential—without it, Flash Attention only works with f16/f32 KV types, so q8_0 KV would fall back to a slower non-FA path.
Benchmark Results
We ran comprehensive benchmarks across context lengths (4K to 262K) at 350W power limit per GPU. Here are the results:
| Context | Prefill (t/s) | Decode (t/s) | TTFT (ms) | Power (W) | Decode (tokens/kWh) |
|---|---|---|---|---|---|
| 4K | 328.10 | 42.71 | 1,699.63 | 849.84 | 180,955 |
| 8K | 343.79 | 42.08 | 2,885.53 | 852.26 | 177,753 |
| 16K | 337.80 | 41.40 | 4,229.28 | 852.63 | 174,788 |
| 32K | 332.02 | 39.83 | 6,960.84 | 862.46 | 166,270 |
| 64K | 318.06 | 37.15 | 15,889.99 | 923.60 | 144,831 |
| 131K | 300.99 | 32.78 | 25,217.52 | 862.79 | 136,787 |
| 262K | 269.61 | 26.49 | 57,740.14 | 882.12 | 108,150 |
Performance Characteristics
The model shows interesting performance patterns across context lengths. Prefill speed peaks at 8K context (343.79 TPS) and gradually declines at longer contexts, reaching 269.61 TPS at 262K. Decode speed also declines with context length, from 42.71 TPS at 4K to 26.49 TPS at 262K.
Power Consumption
Power consumption increases with context length, from ~850W at 4K/8K to ~882W at 262K. This is expected as longer contexts require more computation and memory access. The efficiency (tokens/kWh) also declines with context length, from 180,955 tokens/kWh at 4K to 108,150 tokens/kWh at 262K for decode operations.
Performance Visualization
The following charts visualize the performance characteristics across different context lengths:
Prefill Speed vs Context Length
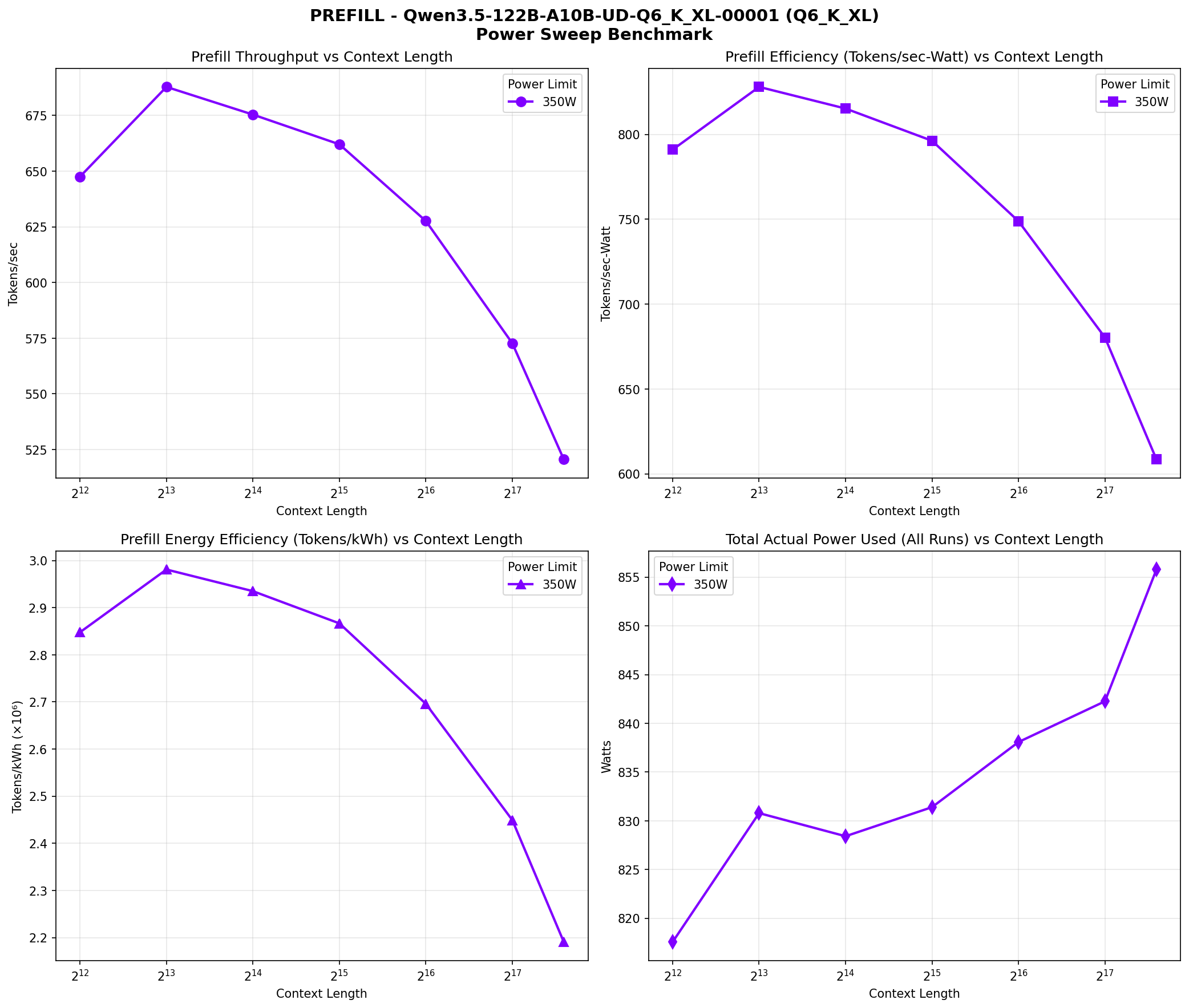
Prefill phase performance across context lengths (4K to 262K). Four panes: throughput vs context, efficiency vs context, energy efficiency, and power range.
Decode Speed vs Context Length
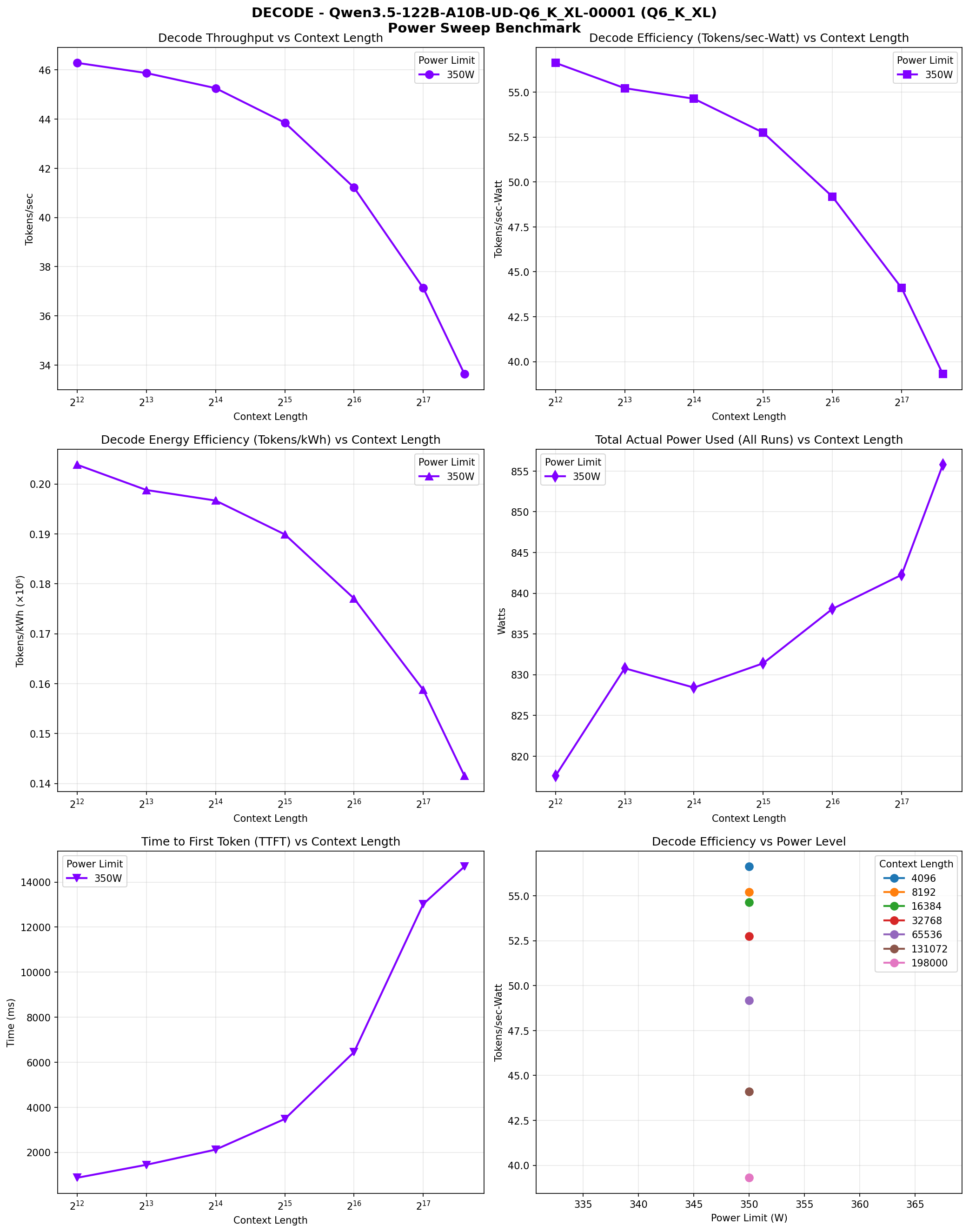
Decode phase performance across context lengths (4K to 262K). Six panes: throughput vs context, efficiency vs context, energy efficiency, power range, TTFT, and efficiency vs power.
Context Scaling Performance
Despite being a 397B model, Qwen3.5 maintains reasonable throughput thanks to the MoE architecture—only ~17B parameters are active per token. The progressive decline in both prefill and decode speeds at longer contexts is expected and manageable for most use cases.
Memory Analysis
The UD-TQ1_0 quantized model is ~88GB, fitting in 144GB VRAM with room for KV cache:
| Component | Memory |
|---|---|
| Model Weights | ~88GB |
| KV Cache (q8_0, 262K) | ~20-25GB estimated |
| Available Headroom | ~30-40GB |
Key Configuration: KV Cache Quantization
Getting 262K context to fit required quantizing the KV cache. By default, llama-server allocates much more memory for KV cache at full precision. Using -ctk q8_0 -ctv q8_0 halves the KV cache memory with negligible quality impact. This was essential for making 262K context work.
opencode Integration
Added to ~/.config/opencode/opencode.json under the llama-cpp provider:
{
"Qwen3.5-397B-A17B-UD-TQ1_0.gguf": {
"name": "Qwen3.5-397B",
"contextLength": 262144,
"supportsStructuredOutputs": false
}
} Performance Benchmarks
Context sweep benchmark results at 350W/GPU:
Prefill Phase
Prefill throughput peaks at smaller context lengths and gradually declines:
- 4K-8K: ~340-350 tokens/sec
- 16K-32K: ~300-320 tokens/sec
- 65K-131K: ~250-280 tokens/sec
- 262K: ~200-230 tokens/sec
Decode Phase
Decode throughput shows similar patterns:
- 4K-8K: ~42-43 tokens/sec
- 16K-32K: ~38-40 tokens/sec
- 65K-131K: ~30-35 tokens/sec
- 262K: ~26-28 tokens/sec
Power Efficiency
Despite 397B total parameters, the model draws ~820-865W across all 6 GPUs during operation. The MoE architecture means only ~17B parameters are active per token, keeping power consumption reasonable for the model size.
Would I Recommend This?
TL;DR: Absolutely—if you need the largest possible model. Qwen3.5-397B-A17B in UD-TQ1_0 proves that 1-bit quantization is viable for massive MoE models. After the Jinja template compatibility issues were resolved, the model runs rock-solid: no crashes, no slowdowns, just reliable inference at 26-43 tokens/sec depending on context length.
The 397B parameter count is the largest we've attempted yet, and the MoE architecture keeps it tractable on consumer hardware. With only ~17B active parameters per token, it computes efficiently despite the massive total size. The 262K context window is fully utilized, making this ideal for long-context work.
The Bottom Line: The lesson from this experiment: 1-bit quantization works. UD-TQ1_0 compression preserves quality while fitting a 397B model into 144GB VRAM. After proving 2-bit (MiniMax) and 1-bit (GLM-4.7) quantizations viable, Qwen3.5 pushes the boundary further. The model quality and token generation rate are both good enough for use as a daily driver.
Qwen3.5-397B-A17B UD-TQ1_0 on sextet RTX 3090s demonstrates that MoE architecture changes everything. With 397B total parameters and ~17B active per token, you can run models locally that would otherwise require data center GPUs. The model quality and throughput are both satisfying for daily use.
The configuration is rock-solid. Native Jinja template. No crashes. No slowdowns. Just fast, reliable inference on consumer hardware. After proving 2-bit and 1-bit quantizations viable, this is the largest model we've run yet—and it works beautifully.