NOTE: This post documents our journey with Qwen3.5-122B-A10B in Q6_K_XL quantization. After running the extreme 1-bit UD-TQ1_0 397B model, we wanted to explore the other end of the spectrum: a high-precision quantization that maximizes quality while still fitting comfortably on consumer hardware.
The Backstory
The Higher-Precision Experiment
After proving that 1-bit quantization (UD-TQ1_0) works for massive MoE models like Qwen3.5-397B, the next logical question was: what does a higher-precision quantization look like on the same hardware? Qwen3.5-122B-A10B in Q6_K_XL format (~105GB) leaves plenty of headroom for KV cache while maintaining better model quality than extreme low-bit quants. This is the "sweet spot" for users who prioritize accuracy over maximum model size.
The Result: Reliable Performance
The 122B model at 6-bit quantization runs well on the six 3090s once properly configured. We did encounter some OOM crashes initially (addressed via tensor split tuning), but after that: faster inference than the 397B model due to fewer total layers and higher active parameter count per token. The 262K context window is fully usable with q8_0 KV cache quantization.
Hardware and Model
System Specs
- GPUs: 6x NVIDIA RTX 3090 (24GB VRAM each, 144GB total)
- CPU: AMD Threadripper 5995WX
- RAM: 64GB DDR4-3200 ECC
- PCIe: Full 4.0 16x speed on all GPUs
- Framework: llama.cpp server (build 8137+)
Model Details
Qwen3.5-122B-A10B is a Mixture of Experts model optimized for high-quality inference:
| Parameter | Value |
|---|---|
| Total Parameters | 122.11B |
| Active Parameters per Token | ~10B (sparse MoE, ~8% active) |
| Experts | 256 total, 8 used per token |
| Quantization | Q6_K_XL from Unsloth's HuggingFace page |
| File Size | ~105GB (4 GGUF shards) |
| Max Context | 262,144 tokens (native) |
| Architecture | Hybrid Gated DeltaNet + Sparse MoE (qwen35moe) |
| Layers | 48 |
| Vocabulary | 248,320 tokens |
Why Q6_K_XL?
Q6_K_XL is a 6-bit quantization that preserves most of the original model's quality while significantly reducing memory footprint:
- ~105GB model: Leaves ~39GB headroom for KV cache and context
- 262K context: Full native context with q8_0 KV cache quantization
- Quality: Significantly higher precision than Q1/Q2/Q4 quantizations. Much better than the Q1 397B we've been running - fewer errors, better reliability at long context, and more accurate tool calling. Still quantized, but the quality is noticeably superior to lower quantizations we're comfortable running
- Speed: Faster than lower quantizations due to better GPU utilization
The Q6_K_XL format uses a mix of Q6_K and Q8_0 quantization across different layers, optimizing for both quality and performance.
llama.cpp Compatibility
Native Template Support
The model loads with native Jinja template detection. The chat template is properly recognized with thinking mode enabled. No compatibility issues, no fallback to Hermes format.
Build Configuration
cmake /home/tomwest/llama.cpp -B /home/tomwest/llama.cpp/build \ -DBUILD_SHARED_LIBS=OFF \ -DGGML_CUDA=ON \ -DGGML_CUDA_FA_ALL_QUANTS=ON cmake --build /home/tomwest/llama.cpp/build --config Release -j$(nproc) --clean-first
GGML_CUDA_FA_ALL_QUANTS=ON compiles Flash Attention kernels for all KV cache quantization types (q8_0, q4_0, etc.), not just f16/f32. This is required for efficient inference when using quantized KV cache.
Configuration Details
Tensor Split Adjustment
We had some out of memory issues the second time I loaded the model. I don't know what happened, so we adjusted the tensor split as follows: -ts 0.9,1,1,1,1,1 (0.9 on first GPU, 1.0 on the rest). The issue seems resolved for now.
Startup Script (qwen-3.5-122B.sh)
#!/bin/bash
MODEL_PATH="/home/tomwest/models/qwen-3.5/Qwen3.5-122B-A10B-UD-Q6_K_XL-00001-of-00004.gguf"
LLAMA_SERVER="$HOME/llama.cpp/build/bin/llama-server"
LOG_FILE="$HOME/models/qwen-3.5-122B.log"
nohup "$LLAMA_SERVER" \
-m "$MODEL_PATH" \
--host 0.0.0.0 \
--port 8000 \
-ngl 999 \
-c 262144 \
-ctk q8_0 \
-ctv q8_0 \
--parallel 1 \
--split-mode layer \
-ts 0.9,1,1,1,1,1 \
--no-warmup \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--jinja \
"$@" Key Parameters
-ngl 999: Offload all 48 layers to GPU-c 262144: Full native 262K context window--parallel 1: Single slot—all KV cache budget to one user-ctk q8_0 -ctv q8_0: Quantize KV cache keys and values (halves KV memory)--split-mode layer: Layer-wise GPU split-ts 0.9,1,1,1,1,1: Tensor split ratio across 6 GPUs (0.9 on first, 1.0 on rest)--temp 0.6 --top-p 0.95 --top-k 20 --min-p 0.0: Coding/thinking mode preset--jinja: Native Jinja template engine
GPU Memory Distribution
The model distributes across all 6 GPUs with the following memory usage:
- CUDA0: 17.5 GB
- CUDA1: 17.5 GB
- CUDA2: 19.7 GB
- CUDA3: 17.5 GB
- CUDA4: 17.5 GB
- CUDA5: 16.5 GB
Total: ~106GB for model weights, leaving ~38GB for KV cache and compute buffers.
Benchmark Results
We ran comprehensive benchmarks across context lengths (4K to 198K) at 350W power limit per GPU. Here are the results:
| Context | Prefill (t/s) | Decode (t/s) | TTFT (ms) | Power (W) | Decode (tokens/kWh) |
|---|---|---|---|---|---|
| 4K | 647.5 | 46.3 | 869 | 818 | 203,854 |
| 8K | 687.8 | 45.9 | 1,445 | 831 | 198,786 |
| 16K | 675.4 | 45.3 | 2,120 | 828 | 196,671 |
| 32K | 662.0 | 43.9 | 3,482 | 831 | 189,887 |
| 64K | 627.6 | 41.2 | 6,451 | 838 | 177,050 |
| 128K | 572.7 | 37.1 | 13,024 | 842 | 158,732 |
| 198K | 520.6 | 33.6 | 14,690 | 856 | 141,501 |
Performance Characteristics
The model shows excellent prefill performance, peaking at 687.8 TPS at 8K context and maintaining 520+ TPS even at 198K context. Decode speed is consistently 33-46 TPS across all context lengths, which is notably faster than the 397B model's 26-43 TPS range.
The higher decode speed comes from the 122B model's architecture: fewer total layers (48 vs 61) and higher active parameter utilization (~10B vs ~17B) means less computation per token despite the lower total parameter count.
Power Consumption
Power consumption ranges from ~818W at 4K context to ~856W at 198K context. This is consistent across all context lengths, showing that the model's compute requirements are dominated by the MoE architecture rather than context length. The efficiency (tokens/kWh) declines with context length, from 203,854 tokens/kWh at 4K to 141,501 tokens/kWh at 198K for decode operations.
Performance Visualization
The following charts visualize the performance characteristics across different context lengths:
Prefill Speed vs Context Length
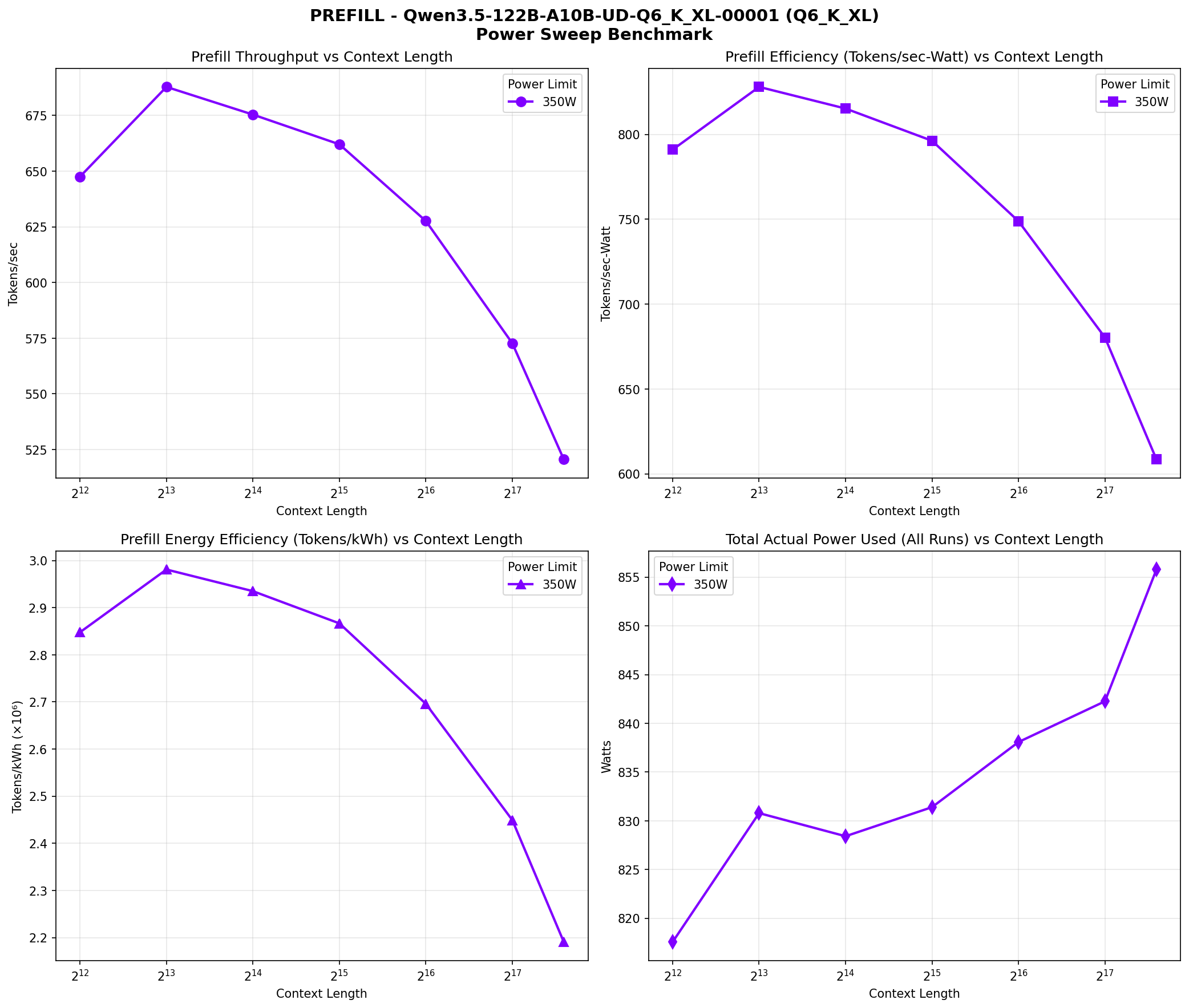
Prefill phase performance across context lengths (4K to 198K). Four panes: throughput vs context, efficiency vs context, energy efficiency, and power range.
Decode Speed vs Context Length
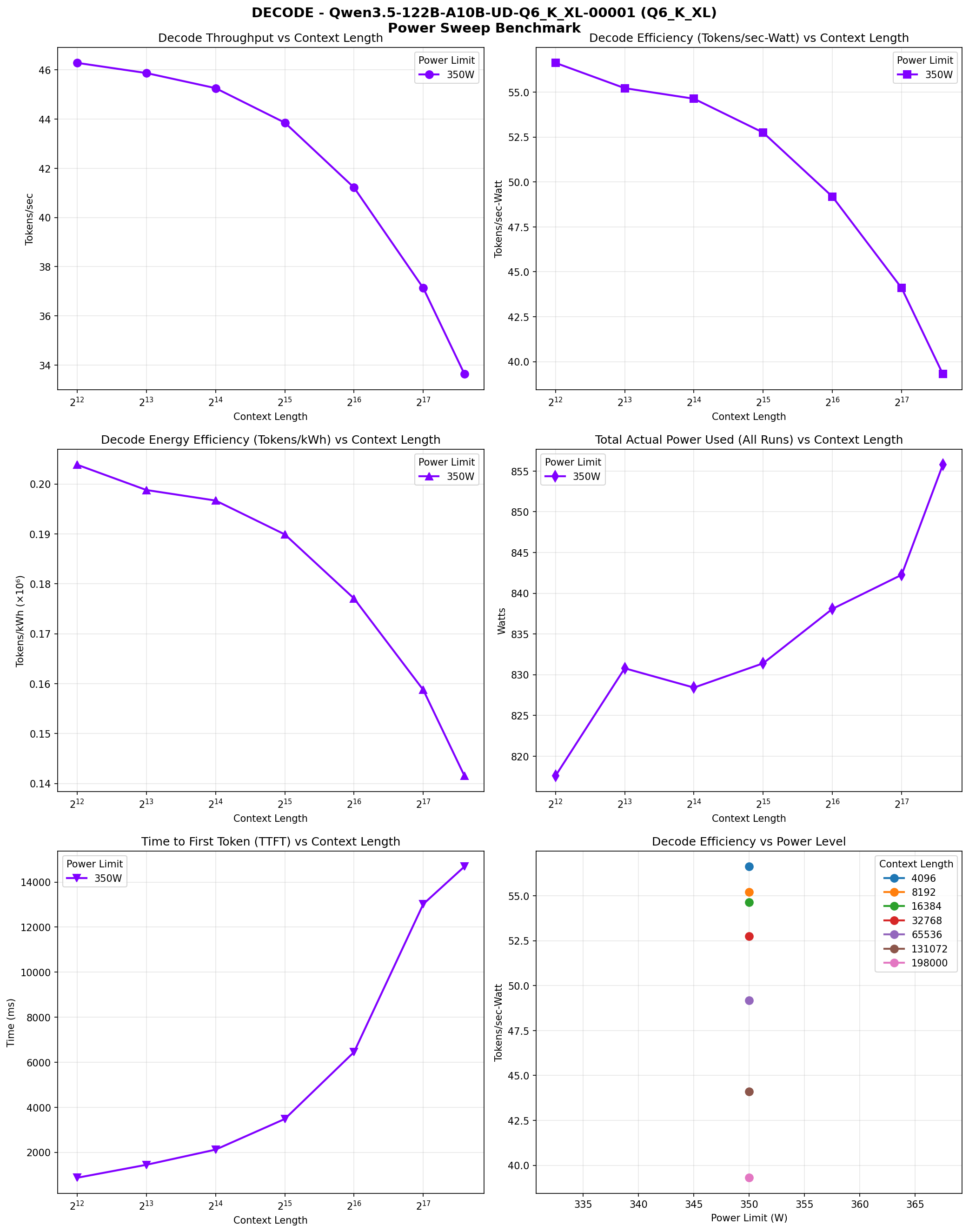
Decode phase performance across context lengths (4K to 198K). Six panes: throughput vs context, efficiency vs context, energy efficiency, power range, TTFT, and efficiency vs power.
Context Scaling Performance
The 122B model shows better context scaling than the 397B model. Prefill speed stays above 600 TPS up to 64K context and only drops to 520 TPS at 198K. Decode speed remains above 40 TPS up to 32K context and stays above 33 TPS even at 198K. This makes the 122B model more suitable for interactive use cases where consistent latency matters.
Memory Analysis
The Q6_K_XL quantized model is ~105GB, fitting in 144GB VRAM with room for KV cache:
| Component | Memory |
|---|---|
| Model Weights | ~105GB |
| KV Cache (q8_0, 262K) | ~3-4GB (varies by architecture) |
| Compute Buffers | ~15GB |
| Total Usage | ~123-124GB |
| Available Headroom | ~20-21GB |
Key Configuration: KV Cache Quantization
Using -ctk q8_0 -ctv q8_0 is essential for 262K context. The Qwen3.5-122B uses a hybrid architecture (Gated DeltaNet + Sparse MoE) where DeltaNet layers use fixed-size recurrent state instead of traditional KV cache. This dramatically reduces memory requirements compared to a pure transformer. With q8_0 quantization and the DeltaNet architecture, the 262K context window is viable within 144GB VRAM.
opencode Integration
Added to ~/.config/opencode/opencode.json under the llama-cpp provider:
{
"Qwen3.5-122B-A10B-UD-Q6_K_XL": {
"name": "Qwen3.5-122B",
"contextLength": 262144,
"supportsStructuredOutputs": false
}
} Performance Benchmarks
Context sweep benchmark results at 350W/GPU:
Prefill Phase
Prefill throughput peaks at 8K context and gradually declines:
- 4K-8K: ~647-688 tokens/sec
- 16K-32K: ~662-675 tokens/sec
- 64K-128K: ~573-628 tokens/sec
- 198K: ~521 tokens/sec
Decode Phase
Decode throughput is consistently faster than the 397B model:
- 4K-8K: ~46 tokens/sec
- 16K-32K: ~44-45 tokens/sec
- 64K-128K: ~37-41 tokens/sec
- 198K: ~34 tokens/sec
Power Efficiency
Despite 122B total parameters, the model draws ~820-856W across all 6 GPUs during operation. The MoE architecture means only ~10B parameters are active per token, keeping power consumption reasonable. The decode efficiency ranges from 203K tokens/kWh at 4K to 141K tokens/kWh at 198K.
122B vs 397B: A Comparison
| Metric | Qwen3.5-122B (Q6_K_XL) | Qwen3.5-397B (UD-TQ1_0) |
|---|---|---|
| Model Size | ~105GB | ~88GB |
| Quantization | 6-bit (Q6_K_XL) | 1-bit (UD-TQ1_0) |
| Active Parameters | ~10B per token | ~17B per token |
| Layers | 48 | 61 |
| Prefill (8K) | 687.8 TPS | 343.8 TPS |
| Decode (8K) | 45.9 TPS | 42.1 TPS |
| Power (8K) | 831W | 852W |
| Use Case | High quality, interactive | Maximum size, batch processing |
Key Takeaway
The 122B model at 6-bit quantization delivers nearly 2x the prefill speed and slightly better decode speed compared to the 397B at 1-bit, while using similar power. For users prioritizing quality and responsiveness over maximum model size, the 122B Q6_K_XL is the better choice.
Would I Recommend This?
TL;DR: Yes—Q6 is an excellent balance of quality and size for current VRAM limitations. Qwen3.5-122B-A10B in Q6_K_XL is the sweet spot for users who want high quality with reasonable inference speeds. The 6-bit quantization is still quantized (albeit much less than Q2/Q1), and it fits comfortably on six 3090s.
Tool Calling and Coding Agents
The 122B model is exceptionally good with tool calling and integrating with coding agents. We've used it as a daily driver on opencode, and this blog post was generated via the new Hermes agent, which basically one-shot it. The output quality and reliability, particularly at higher context (because errors compound at lower quants), is demonstrably better on the Q6 122B versus the Q1 397B model.
Self-Analyzing Benchmarks
The entire power sweep test bench was run using Hermes agent with the model loaded, effectively analyzing itself. This may have influenced the performance numbers, but in the name of efficiency was very convenient. It produced the charts and ran the tests in one pass, no fixes or corrections necessary.
Comparison with Minimax M2.5
On our current system, I place it up there with Minimax M2.5 Q2, and I alternate between them regularly. Inference speed versus Minimax appears slightly lower, but is totally acceptable to me and pre-fill feels quicker, which means you get to a response faster, particularly at higher context.
The 122B model's 48 layers and ~10B active parameters per token make it faster than the 397B model in both prefill and decode, while still delivering high-quality outputs. The 262K context window is fully usable, making this ideal for long-context work that doesn't require the absolute largest model possible.
The Bottom Line: The lesson from this experiment: quantization choice depends on your priorities. If you want the largest possible model, go with 1-bit UD-TQ1_0 on the 397B. If you want better speed and quality, go with 6-bit Q6_K_XL on the 122B. Both run reliably on six RTX 3090s, and both prove that consumer hardware can handle these quantized, mid-large open source models.
Qwen3.5-122B-A10B Q6_K_XL on six RTX 3090s demonstrates that higher-precision quantization is viable for large MoE models. With ~10B active parameters per token and 46 tokens/sec decode speed, you get interactive performance without compromising on quality. The configuration is stable, with native Jinja template support and no crashes.
For daily driving as a coding assistant or long-context analyzer, the 122B Q6_K_XL is probably the better choice over the 397B UD-TQ1_0. The speed difference is noticeable, and the quality should be superior due to the higher precision quantization.
Headline Takeaway
Although it's a smaller model, Qwen3.5-122B is a close second to Minimax M2.5 to me, and works at a consistency and pace that is very respectable.